Преобразования базовых типов данных
При рассмотрении типов данных указывалось, какие значения может иметь тот или иной тип и сколько байт памяти он может занимать. В прошлой теме были расмотрены арифметические операции. Теперь применим операцию сложения к данным разных типов:
1
2
| byte a = 4;int b = a + 70; |
Но теперь попробуем применить сложение к двум объектам типа byte:
1
2
| byte a = 4;byte b = a + 70; // ошибка |
При операциях мы должны учитывать диапазон значений, которые может хранить тот или иной тип. Но в данном случае число 74, которое мы ожидаем получить, вполне укладывается в диапазон значений типа byte, тем не менее мы получаем ошибку.
Дело в том, что операция сложения (да и вычитания) возвращает значение типа int, если в операции участвуют целочисленные типы данных с разрядностью меньше или равно int (то есть типы byte, short, int). Поэтому результатом операции
a + 70 будет объект, который имеет длину в памяти 4 байта.
Затем этот объект мы пытаемся присвоить переменной b, которая имеет тип byte и в памяти занимает 1 байт.И чтобы выйти из этой ситуации, необходимо применить операцию преобразования типов:
1
2
| byte a = 4;byte b = (byte)(a + 70); |
Сужающие и расширяющие преобразования
Преобразования могут сужающие (narrowing) и расширяющие (widening). Расширяющие преобразования расширяют размер объекта в памяти. Например:
1
2
| byte a = 4; // 0000100ushort b = a; // 000000000000100 |
1
| 00000100 |
1
| 0000000000000100 |
Сужающие преобразования, наоборот, сужают значение до типа меньшей разядности. Во втором листинге статьи мы как раз имели дело с сужающими преобразованиями:
1
2
| ushort a = 4;byte b = (byte) a; |
0000000000000100
получаем 00000100. Таким образом, значение сужается с 16 бит (2 байт) до 8 бит (1 байт).Явные и неявные преобразования
Неявные преобразования
В случае с расширяющими преобразованиями компилятор за нас выполнял все преобразования данных, то есть преобразования были неявными (implicit conversion). Такие преобразования не вызывают каких-то затруднений. Тем не менее стоит сказать пару слов об общей механике подобных преобразований.Если производится преобразование от безнакового типа меньшей разрядности к безнаковому типу большой разрядности, то добавляются дополнительные биты, которые имеют значени 0. Это называется дополнение нулями или zero extension.
1
2
| byte a = 4; // 0000100ushort b = a; // 000000000000100 |
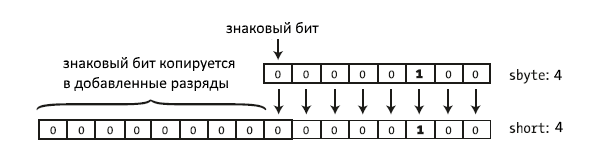
Рассмотрим преобразование положительного числа:
1
2
| sbyte a = 4; // 0000100short b = a; // 000000000000100 |
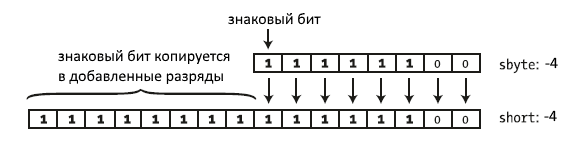
Преобразование отрицательного числа:
1
2
| sbyte a = -4; // 1111100short b = a; // 111111111111100 |
Явные преобразования
При явных преобразованиях (explicit conversion) мы сами должны применить операцию преобразования (операция()).
Суть операции преобразования типов состоит в том, что перед значением указывается в скобках тип, к которому надо привести данное значение:
1
2
3
| int a = 4;int b = 6;byte c = (byte)(a+b); |
byte -> short -> int -> long -> decimal
int -> double
short -> float -> double
char -> int
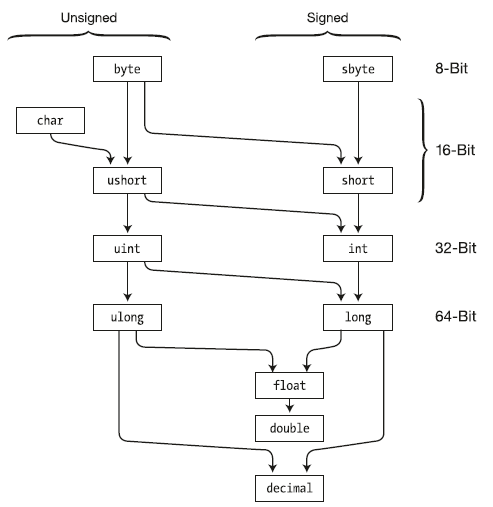
Все безопасные преобразования автоматические преобразования можно описать следующей таблицей:
| Тип | В какие типы преобразуется |
|---|---|
| byte | short, ushort, int, uint, long, ulong, float, double, decimal |
| sbyte | short, int, long, float, double, decimal |
| short | int, long, float, double, decimal |
| ushort | int, uint, long, ulong, float, double, decimal |
| int | long, float, double, decimal |
| uint | long, ulong, float, double, decimal |
| long | float, double, decimal |
| ulong | float, double, decimal |
| float | double |
| char | ushort, int, uint, long, ulong, float, double, decimal |
В остальных случаях следует использовать явные преобразования типов.
Также следует отметить, что несмотря на то, что и double, и decimal могут хранить дробные данные, а decimal имеет большую разрядность, чем double, но все равно значение double нужно явно приводить к типу decimal:
1
2
| double a = 4.0;decimal b = (decimal)a; |
Потеря данных и ключевое слово checked
Рассмотрим другую ситуацию, что будет, например, в следующем случае:
1
2
3
| int a = 33;int b = 600;byte c = (byte)(a+b); |
Однако ситуации разные могут быть. Мы можем точно не знать, какие значения будут иметь числа a и b. И чтобы избежать подобных ситуаций, в c# имеется ключевое слово
checked:
1
2
3
4
5
6
7
8
9
10
11
| try{ int a = 33; int b = 600; byte c = checked((byte)(a + b)); Console.WriteLine(c);}catch (OverflowException ex){ Console.WriteLine(ex.Message);} |
checked приложение выбрасывает исключение о переполнении. Поэтому для его обработки
в данном случае используется конструкция try...catch. Подробнее данную конструкцию и обработку исключений мы рассмотрим позже, а пока надо знать, что
в блок try мы включаем действия, в которых может потенциально возникнуть ошибка, а в блоке catch обрабатываем ошибку.